WarpHammer fuses geometry from an auxiliary image of a different instance of the same object category, improving novel view quality without requiring pose information.
Gemini outputs using the same prompt, showing the limitations of image-based generation for cross-instance object fusion.

Novel view synthesis results using an auxiliary image from a different instance of the same object category. The auxiliary image provides additional geometry without requiring pose information.
Projection-conditioned novel view synthesis (NVS) warps an explicit 3D reconstruction of the input view into the target camera and conditions a generator on the warped rendering. This works well for small viewpoint changes but degrades sharply under large orbital motion: the warp becomes sparse around the orbited object — where hidden surfaces dominate the new view — and mirror-like artifacts emerge, causing the generator to lose both pixel content and the implicit camera cue carried by the warp. We introduce WarpHammer, a training-free framework that resolves this failure mode by augmenting the warped scene with an explicit 3D reconstruction of the object obtained from a native 3D generative prior (e.g., SAM3D). The object reconstruction densifies the foreground region, where the scene warp is most degraded and reconstruction fidelity matters most, restoring both appearance and camera cues without fine-tuning the base model. The same explicit object representation further unlocks a capability current NVS pipelines do not support: incorporating auxiliary views of the object from sources outside the target scene — for example, a casual snapshot of a car paired with a manufacturer studio shot of the same model. We process the reference and auxiliary images jointly with a pretrained multi-view geometry foundation model, which predicts a unified point cloud that we fuse into the 3D object reconstruction. This yields substantially more faithful geometry than single-image reconstruction, without requiring user-provided camera poses for the auxiliary views. On five benchmarks, WarpHammer produces stable novel views at viewpoint deviations where strong baselines collapse, and is the first scene-level NVS method that can naturally fuse auxiliary, pose-unknown object views from an external source.
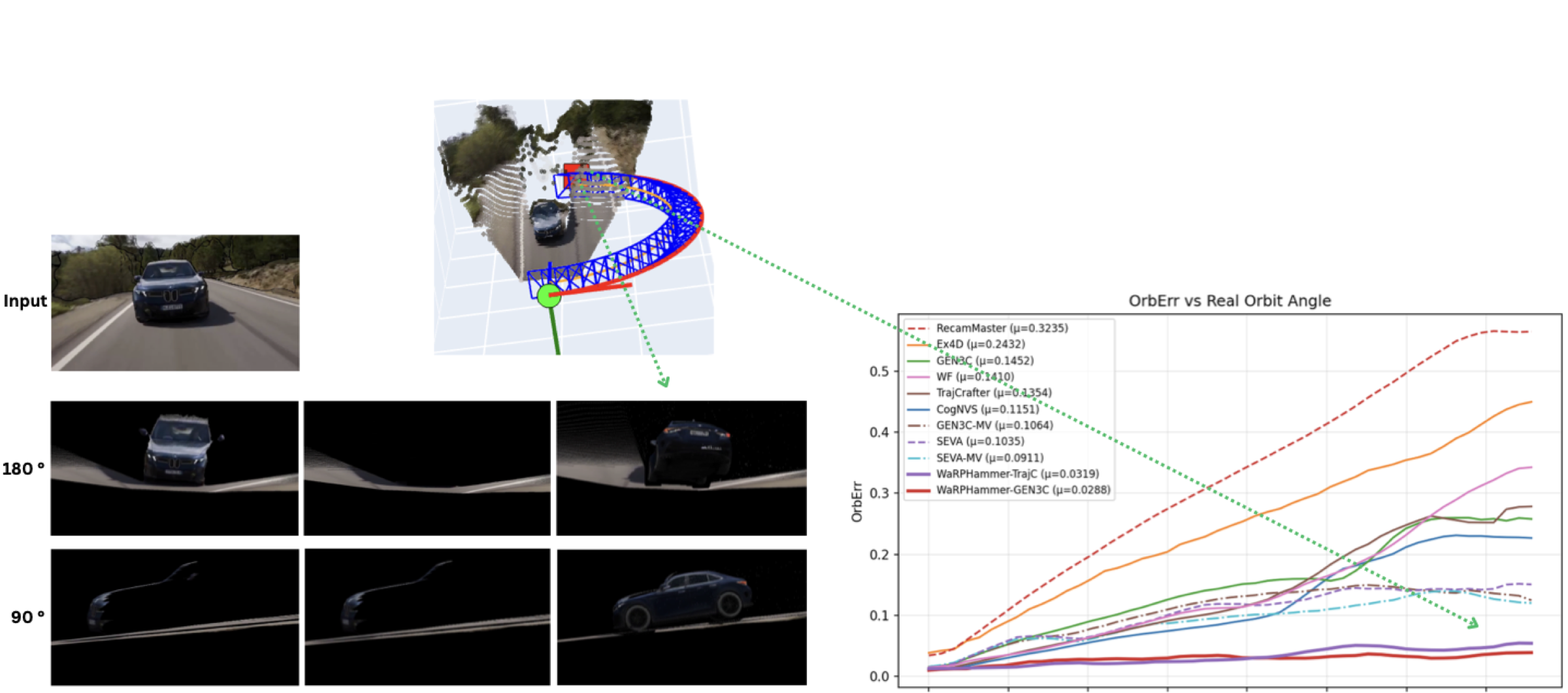
Object-centric densification improves extreme-view synthesis. GEN3C produces sparse outputs with visible artifacts, while WarpHammer remains geometry-consistent. Baselines degrade beyond ~110° viewpoint change, while WarpHammer maintains low error throughout.
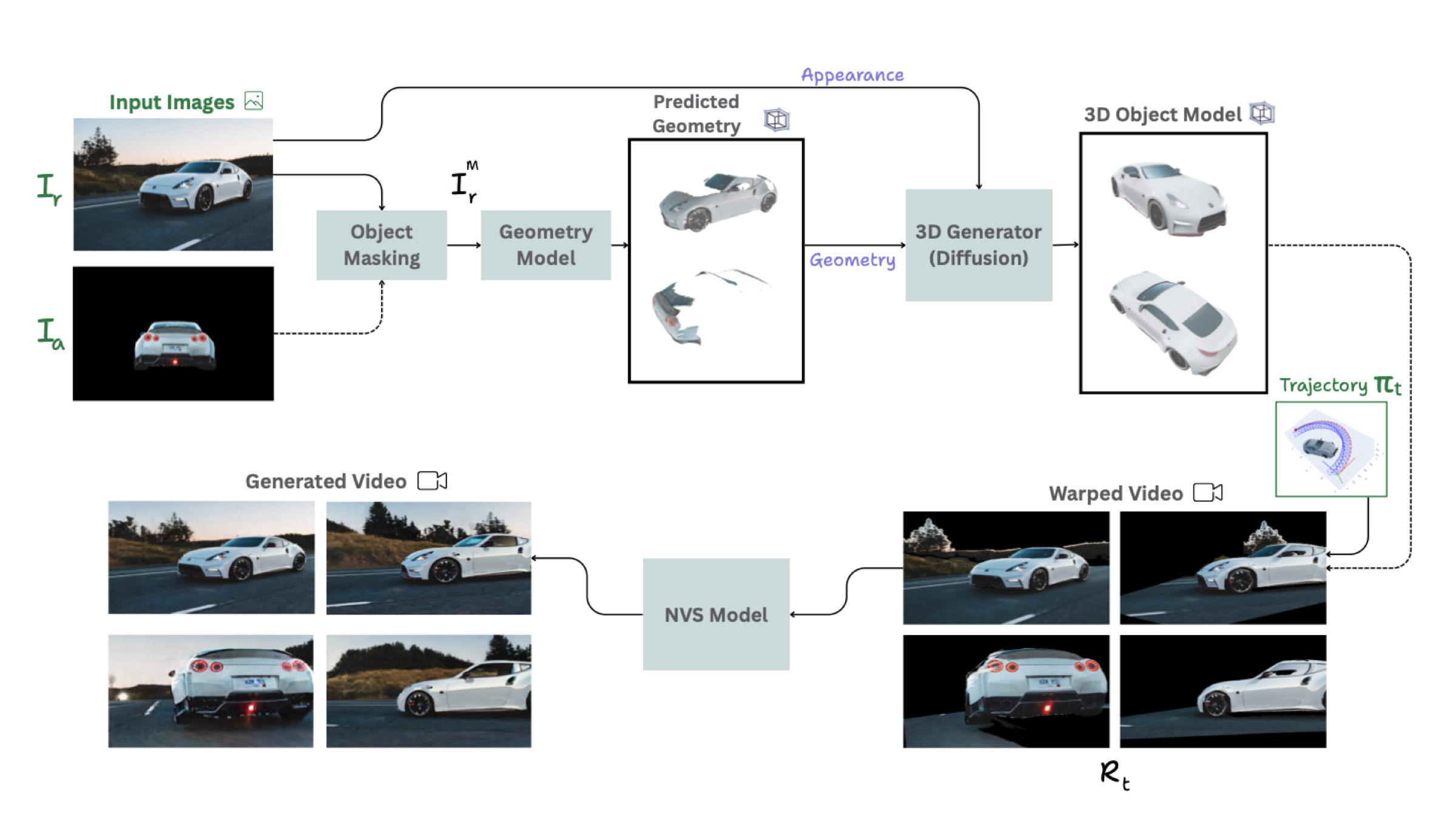
Overview of WarpHammer. Given a reference image and target camera trajectory, WarpHammer builds a densified, geometry-aware point cloud cache for large-viewpoint novel view synthesis. The scene is lifted into 3D via monocular depth, then densified on foreground objects using an explicit reconstruction from a 3D generative prior. An optional auxiliary image can be registered to contribute additional geometry while suppressing appearance transfer. The fused cache conditions a video diffusion model that fills disocclusions while preserving scene identity.
Interactive 3D point clouds. Drag to orbit, scroll to zoom, right-click to pan.
 Input Image
Input Image
 Masked Input
Masked Input
 Masked Back
Masked Back
Drag the slider to compare renderings. All videos are rendered at the same camera trajectory.
 Auxiliary View
Auxiliary View